1. About
Tip
We welcome you to our new platform! In this page you will learn:
what Spider is all about
whether it is suitable for your research project
what are the collaboration options
how to obtain access and work within a Spider project
1.1. Spider at a glance
Spider is a versatile high-throughput data-processing platform aimed at processing large structured data sets. It runs on top of our in-house elastic Cloud. This allows for processing on Spider to scale from many terabytes to even petabytes. Utilizing many hundreds of cores simultaneously Spider can process these datasets in exceedingly short timespans. Superb network throughput ensures connectivity to external data storage systems.
Apart from scaling and capacity, Spider is aimed at interoperability with other platforms. This interoperability allows for a high degree of integration and customization into the user domain. Spider is further enhanced by specific features supporting collaboration, data (re)distribution, private resources or even private Spider instances.
Have a glance here of the main features offered by Spider:
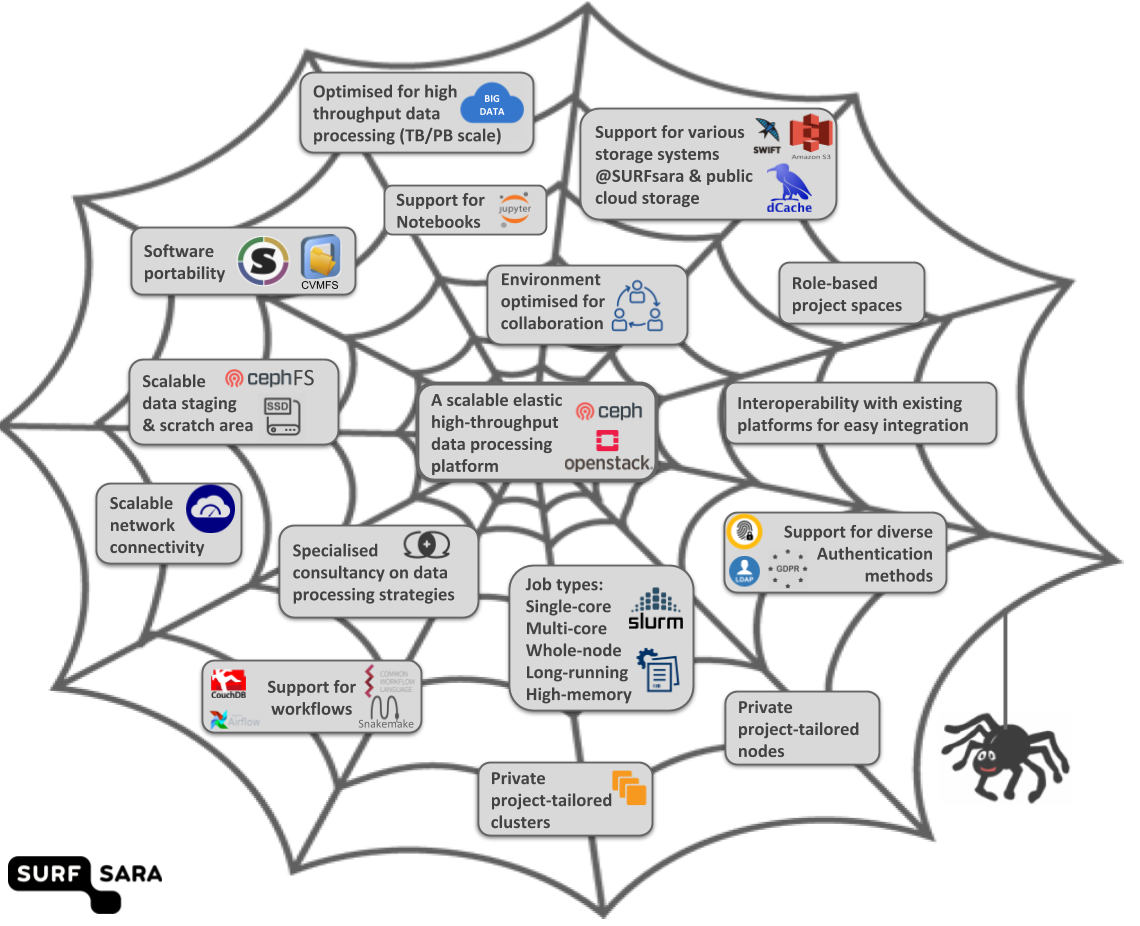
1.2. Platform components
Spider is a feature-rich platform under continuous development. We keep adding new features to the platform in order to meet the needs of researcher projects working with massive datasets.
Spider is built on powerful infrastructure and designed with the following components:
Batch processing cluster (based on Slurm) for generic data processing applications
Batch partitions to enable Single-core, Multi-core, Whole-node, High-memory and Long-running jobs
Large CephFs data staging area (POSIX-compliant filesystem) scales to PBs without loss of performance or stability
Large and fast scratch area’s (NVMe SSDs) on the worker nodes
Fast network uplink (1200 Gbit/s) allowing for scalable parallel data transfers from other SURFsara based storage systems (e.g. dCache, SWIFT), or from external storage systems
Role-based project spaces tailored for data-centric projects
Scientific catalogs for cross-project collaboration
Web access over HTTPS for public data distribution and sharing with external collaborators
Singularity containers for software portability
CVMFS/Softdrive support for software distribution
Jupyter Notebooks
Interactive jobs and direct visualization from within jobs
Specific tooling for data-processing workflows
Workflow management support
Diverse authentication methods
Private resources for special purposes (reservations, private nodes, private clusters)
1.3. Best suited cases
The best-suited cases for Spider are scientific projects with a requirement to process relatively large data sets. For example research projects suitable for Spider that deal with massive datasets are commonly in: Genomics, Proteomics, Earth observation, Astronomical observation, Climate modeling, Engineering or Physics experiments.
You would be eligible for Spider if your project reflects some of the following needs:
Processing of large amount of data of many terabytes to petabytes in short time spans
Processing of large amount of independent simulations and workflows
Interactive processing with user-friendly interfaces for efficient data handling
Industry standard interfaces and other interoperability features
Co-working with your collaborators on the same project-based workspace
Accessing external storage facilities with fast connectivity
Also Spider is a viable alternative for current and potential Grid users who are looking to use a more customizable system. It is a low-threshold platform, as opposed to highly complex Grid platforms that take many months of specialist development before they can start. Being built upon the exact same physical data-processing infrastructure and sharing the same scalable network connectivity as the Grid-based processing environments, Spider offers the same data-parallel processing capabilities as the most powerful Grid platforms.
Note though that while it’s great for data-intensive applications, Spider is not really aimed at:
HPC applications where operations per second are critical
Processing of simulations that require multi-node execution
Applications that cannot be ported onto Linux-based system
1.4. Collaboration
Spider is designed for Big Science which requires collaboration. Spider supports several ways to collaborate, either within your project, across projects, or to external sources.
1.4.1. Project space
Project spaces on Spider are shared workspaces given to team members that enable collaboration through sharing data, software and workflows. Within your project space there are four folders:
Data: Housing source data from data managers
Share: For sharing between project members
Public: For sharing publicly through webviews
Software: Scripts, libraries and tools
Spider enables collaboration for your project with granular access control to your project space through project roles, enabling collaboration for any team structure:
data manager role: designated data dissemination manager; responsible for the management of project-owned data
software manager role: designated software manager; responsible to install and maintain the project-owned software
normal user role: scientific users who focus on their data analysis
1.4.2. Scientific catalog
Collaboration is also possible across different Spider projects. These are cases where different user groups work on projects with different scope and goals but need to (partly) share read-only data (such as observations or biobank data). Spider offers a place for multiple project teams to collaborate by sharing data sets or tools. This workspace is called scientific catalog and it is not offered by default to a project.
The scientific catalog data can be either open to everyone on the platform or private to selected Spider project groups.
The scientific catalog has only one (but important) role:
scientific catalog manager: designated data dissemination SC manager; responsible for populating the catalog and deciding which Spider project groups have read access to that catalog.
1.4.3. Interoperability hotspot
In contrast to many of the processing platforms already available, typically offering an all-inclusive solution within the boundaries of the their environment, Spider is exactly the opposite. It aims to be a connecting platform in a world that has already a lot to offer in terms of storage systems, data distribution and collaboration frameworks, software management and portability systems, and pilot job and task management frameworks. The Spider platform can hook them all together as an interoperability hotspot to support a variety of data processing and data collaboration use cases.
For all external services supported, even services owned by the users themselves, Spider offers optimized configurations and practical guidelines how to connect to these services together into a practical processing environment tailored specifically to each project.
1.5. Project lifecycle
If you decided that Spider sounds suitable for your research project, then you can apply to obtain access and start your project or join an existing one.
1.5.1. Starting a project
For information about the granting routes on Spider please see our Proposals Page.
Before applying for a new project on Spider we suggest you to contact our helpdesk to discuss your project.
1.5.2. Extending a project
You can apply for a time or resource capacity extension for an existing project on Spider by requesting extra resources. Please see our Proposals Page or contact our helpdesk.
1.5.3. Joining an existing project
If you are interested to join an existing project please contact our our helpdesk. Upon your request we will verify with the project PI whether we can give you access to the project and what your project role would be.
1.5.4. Ending a project
Once your project ends, all the relevant data and accounts will be removed according to the Usage Agreement terms and conditions.
See also
Still need help? Contact our helpdesk